-
 Streams
Streams
-
Compute
- Overview
- Group By Ranges & Buckets
- Data Explorer Guide
- Video Completion Funnel
- Saved Queries
- Compute Pricing Guide
- Custom Ad Performance
- Session Timing Metrics
- Cohort Analysis
- Retention Analysis
- Funnel Analysis
- Creating a Funnel with an OR Condition
- Stripe Revenue Queries
- Create a Email Nightly Report
- Query Tuning
- Cached Queries
- Cached Datasets
- Paid Session Metrics
- User Engagement
-
Visualize
Amazon S3 Integration
Stream inbound event data into an S3 bucket.
When you activate this integration, we will stream your full-resolution, enriched event data to Amazon Simple Storage Service (S3), in your Amazon account.
This is useful for a few reasons:
-
Routing events to third parties
- Use AWS Lambda to route all, or a subset of, your events to any third-party service with an event ingestion API. Great use cases include CRMS such as Hubspot or Salesforce.
-
Backups
- This gives you a scaleable, durable, and secure backup of your data, which is stored in gzip-compressed text files.
- AWS and APN partners can help you meet Recovery Time Objectives, Recovery Point Objectives, and compliance requirements.
-
SQL-based analysis
- While Keen Compute is great for building analytics features into your products and analysis-driven automation into your workflows, nothing beats SQL for data exploration. We recommend combining our S3 Integration with Amazon Athena (via processing from Amazon Glue) or Redshift to accomplish this.
Note: If there are other cloud file systems you would like to stream your enriched data, we would love to hear from you. We may already be in private beta with those services.
Configuring your Keen project
- If it isn’t already turned on, reach out to us to have this feature turned on.
- Find the project you’d like to have streaming data to S3 and navigate to the Streams page.
- Click on the “Configure S3 Streaming” button.
- Configure your S3 account as mentioned in the Keen to S3 Instructions.
- Enter the bucket you’d like your Keen data to flow into.
- Click the “Update” button.
Keen to S3 Instructions
- Sign in to the AWS Console and navigate to the S3 Console.
- Select the bucket you wish to use.
- Select the Permissions section.
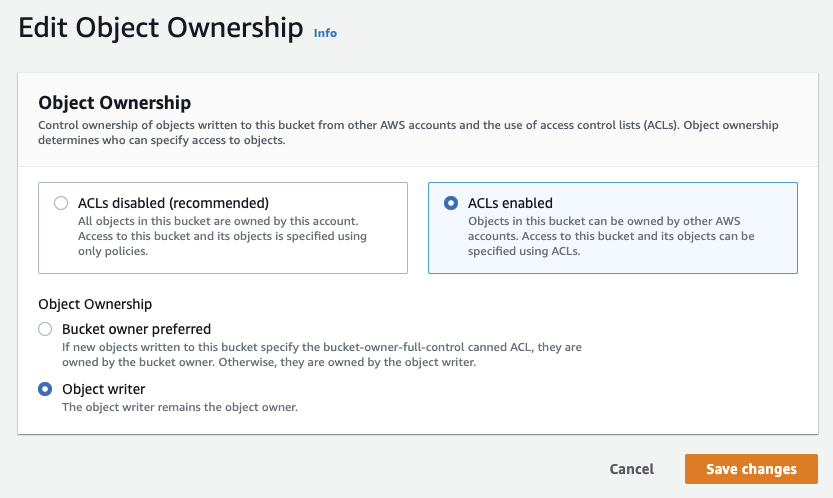
- Edit the Object Ownership.
- Select ACLs enabled and set Object Ownership to Object writer.
- Click the “Save changes” button.
- Head to the Access control list (ACL) section and click Edit.
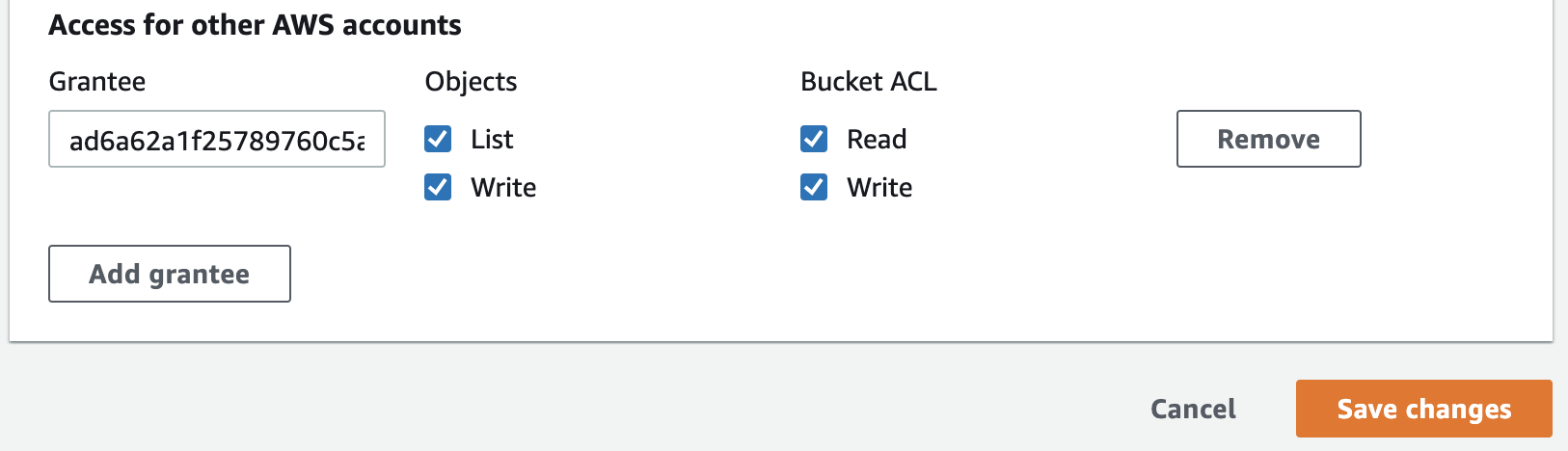
- Scroll down to the bottom of the screen and click Add grantee under the Access for other AWS accounts subsection.
- In the Grantee field enter ad6a62a1f25789760c5a581938a7ee06a865d0b95cc5b1b900d31170da42a48c and ensure all checkboxes are checked (“List objects”, “Write objects”, “Read bucket permissions”, “Write bucket permissions”).
- Click the “Save changes” button.
AWS S3 provides a “Default encryption” feature. If you decide to encrypt data stored in a selected bucket you have two options:
- AES-256 works without any additional effort.
- AWS-KMS requires additional configuration (please contact our support).
How your data streams to S3
Data is streamed to S3 in fixed time increments (default is every 5 minutes). Assuming your S3 bucket is called “MyBucket”, the default bucket/key structure will look as follows:
MyBucket/<project_id>/<ISO-8601_timestamp>/<event_collection>/<project_id>-<event_collection>-<ISO-8601_timestamp>.json.gz
An example structure looks like this:
MyBucket
└── 530a932c36bf5a2d230
├── 2014-01-01T00:05:00.000Z
│ ├── pageviews
│ │ └── 530a932c36bf5a2d230-pageviews-2014-01-01T00:05:00.000Z.json.gz
│ ├── signups
│ │ └── 530a932c36bf5a2d230-signups-2014-01-01T00:05:00.000Z.json.gz
│ └── logins
│ └── 530a932c36bf5a2d230-logins-2014-01-01T00:05:00.000Z.json.gz
└── 2014-01-01T00:10:00.000Z
├── pageviews
│ └── 530a932c36bf5a2d230-pageviews-2014-01-01T00:10:00.000Z.json.gz
├── signups
│ └── 530a932c36bf5a2d230-signups-2014-01-01T00:10:00.000Z.json.gz
└── logins
└── 530a932c36bf5a2d230-logins-2014-01-01T00:10:00.000Z.json.gz
Keen also supports an alternate streaming path configuration that’s a bit friendlier if you plan on using something like Amazon Athena in the future. If you wish to use it, please contact support. The bucket/key structure for this alternative version look’s as follows:
MyBucket/<project_id>/<event_collection>/<ISO-8601_timestamp>/<project_id>-<event_collection>-<ISO-8601_timestamp>.json.gz
An example structure looks like this:
MyBucket
└── 530a932c36bf5a2d230
├── pageviews
│ ├── 2018-11-30T00:05:00.000Z
│ │ └── 530a932c36bf5a2d230-pageviews-2018-11-30T00:05:00.000Z.json.gz
│ └── 2018-11-30T00:10:00.000Z
│ └── 530a932c36bf5a2d230-pageviews-2018-11-30T00:10:00.000Z.json.gz
├── signups
│ ├── 2018-11-30T00:05:00.000Z
│ │ └── 530a932c36bf5a2d230-signups-2018-11-30T00:05:00.000Z.json.gz
│ └── 2018-11-30T00:10:00.000Z
│ └── 530a932c36bf5a2d230-signups-2018-11-30T00:10:00.000Z.json.gz
└── logins
├── 2018-11-30T00:05:00.000Z
│ └── 530a932c36bf5a2d230-logins-2018-11-30T00:05:00.000Z.json.gz
└── 2018-11-30T00:10:00.000Z
└── 530a932c36bf5a2d230-logins-2018-11-30T00:10:00.000Z.json.gz
Error Scenarios
There may be times in which our system cannot write all the events for a given time period. This can be caused by network latency, 3rd party system failure, or a complication arising within our own system. To account for this, we need the ability to update previously written folders. When this happens, we will add new keys to the bucket with an additional incremental suffix as well as update the MyBucket/batches folder with the additional key. Please note, that any file with the additional incremental suffix, only contains the data that was not uploaded successfully during the previous attempts.
An example of a bucket with this:
MyBucket
└── 530a932c36bf5a2d230
├── 2014-01-01T00:05:00.000Z
│ ├── pageviews
│ │ ├── 530a932c36bf5a2d230-pageviews-2014-01-01T00:05:00.000Z.json.gz
│ │ └── 530a932c36bf5a2d230-pageviews-2014-01-01T00:05:00.000Z.json.gz.1
│ ├── signups
│ │ └── 530a932c36bf5a2d230-signups-2014-01-01T00:05:00.000Z.json.gz
│ └── logins
│ └── 530a932c36bf5a2d230-logins-2014-01-01T00:05:00.000Z.json.gz
├── 2014-01-01T00:10:00.000Z
│ ├── pageviews
│ │ └── 530a932c36bf5a2d230-pageviews-2014-01-01T00:10:00.000Z.json.gz
│ ├── signups
│ │ └── 530a932c36bf5a2d230-signups-2014-01-01T00:10:00.000Z.json.gz
│ └── logins
│ └── 530a932c36bf5a2d230-logins-2014-01-01T00:10:00.000Z.json.gz
└── batches
└── 2014-01-01T00:12:12.123Z-pageviews
The file that was placed in the “batches” folder contains the timestamp that a new file was placed into an existing timeframe. That file contains the fully qualified key for the additional data.
In this example, the contents would be:
530a932c36bf5a2d230/2014-01-01T00:05:00.000Z/pageviews/530a932c36bf5a2d230-pageviews-2014-01-01T00:05:00.000Z.json.gz.1
