Blog
Featured Post
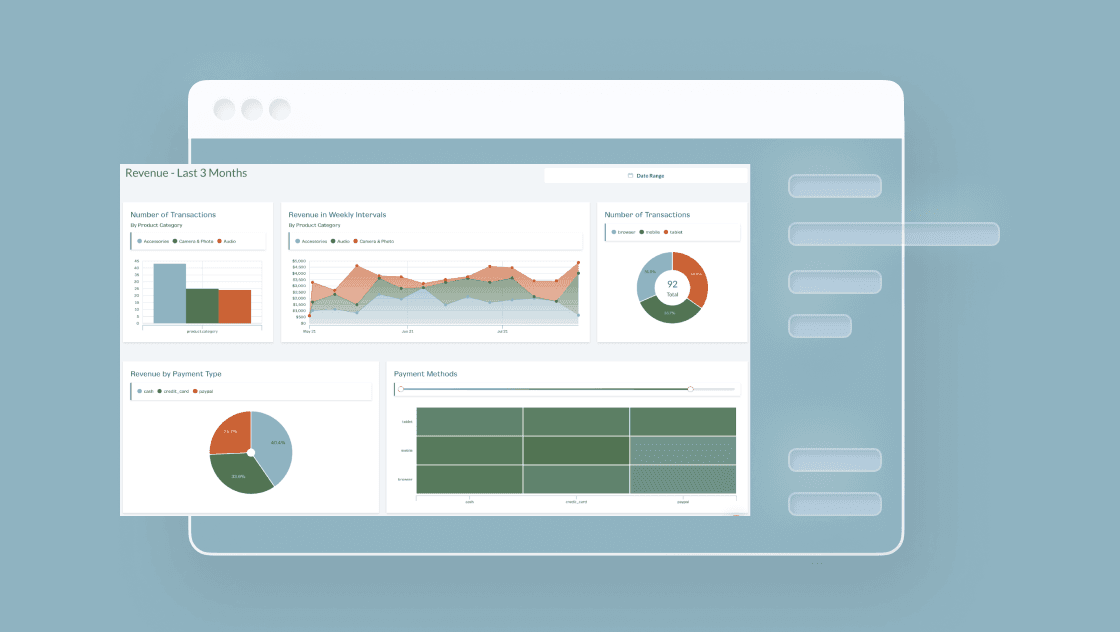
Introducing: New Dashboard Creator
Build interactive dashboards that are cohesive with your brand and then seamlesly share them with relevant stakeholders using Keen’s new Dashboard Creator.








G2 High Performer – Spring 2020
Keen was named a High Performer in the G2 Crowd’s Spring 2020 Grid Report for Business Intelligence. We’re proud to have a high satisfaction rating based on verified user reviews.
GoodFirms Top Big Data Analytics Software
Keen is recognized by GoodFirms as an industry leader in the space of Big Data Analytics. GoodFirms is a B2B research and review platform for top technology + software service companies.

SourceForge – Open-Source and Business Software Platform
SourceForge is “an Open Source community resource dedicated to helping open source projects be as successful as possible.” They also provide reviews on business software and IT services.
