
In the world of big data, event streaming architecture enables businesses to capture massive volumes of real-time data to be used in a wide variety of use cases. From monitoring and alerting, to training ML/AI algorithms for predictive analytics, to deploying event-driven products, leveraging event streaming enables companies to launch disruptive, differentiated solutions.
Capturing and processing this data is a significant lift for engineering teams—we’ve created a handy guide that covers this topic in more detail—but data capture is only one piece of a complex puzzle. Being able to simply collect this data is not enough, teams need to have a full-fledged solution that enables them to turn data into actions and insights.
A critical first step to creating a robust solution is considering how data needs to be stored. There are two prominent storage frameworks to evaluate when building a high performance distributed system: temporary storage and persistent storage. In this article, we will:
- Cover the differences between persistent and temporary storage for event-driven applications vs. real-time data analytics requirements.
- Introduce options for persistent storage on Apache Kafka event streaming architecture
- Explore DIY approaches to persistent storage for event streaming architecture
- Discuss how Platform-as-a-Service (PaaS) products simplify the configuration of persistent storage for small-to-midsize businesses (SMBs)
Introduction to Event Streaming: SQL, NoSQL, & Keystore DBs
Event streaming architecture is based on pub-sub messaging and event logs which record state changes on apps or devices via APIs. Complex event streaming architecture has two primary sources of input, streaming data from applications and events generated from batch processing. Applications generate real-time events from activity on web servers, network security monitors, advertising tracking, web/mobile applications, and IoT device sensors. Batch processes generate events from activity related to scheduled billing or other triggered processes by variable computation. All of this event data is recorded in persistent or cached storage depending on the architecture.
Due to the massive volumes of event messages generated for high traffic websites and applications, businesses are challenged with managing terabytes (TBs) or petabytes (PBs) of data. Companies often turn to Apache Kafka, an open-source distributed event streaming platform, for capturing and processing these massive volumes of data. In fact, Kafka is used by 80% of all Fortune 100 and thousands of companies overall. In addition to Kafka’s event streaming functionality, it also provides a real-time message queue for temporary event log storage as pictured below.
With temporary storage, data is only available on an event streaming platform for a limited time, whereafter it must be transferred to offsite facilities for warehousing like Azure Blob/Data Lake, AWS S3, or Snowflake. This is an acceptable solution for applications that need to leverage event data in real-time and then perform historical analysis on transferred data at a later date. Challenges arise when a real-time search and data analytics solution is needed due to the division between recent and historical archives. For these applications, a persistent storage solution is needed as well.
With persistent storage, systems keep data on the same platform for reference and access by SQL, APIs, or other query languages like CQL. Event logs provide much of the source information for “big data” archives. The event logs in Apache Kafka can be stored for access in a variety of database formats across SQL & NoSQL frameworks. Data architects commonly utilize a combination of SQL, NoSQL, and Keystore database solutions including Apache Cassandra, BigTable, Amazon Redshift, CosmosDB, IBM DB2, and Amazon Athena to achieve this.
Database Storage Solutions for Apache Kafka Event Streaming Infrastructure:
- Apache Cassandra is a highly-scalable, fault-tolerant NoSQL database used in Keen’s multi-tenant managed event streaming infrastructure platform for persistent storage.
- Confluent’s ksqlDB is a proprietary SQL solution that works with the Kafka Streams client library for storage and can be run in multiple configurations on public cloud hardware.
- Cloud Bigtable is a fully managed, NoSQL database with consistent, low-latency, high-throughput data access, used on GCP for event streaming architecture.
- Amazon Kinesis Data Streams is used for storage of data on AWS event stream infrastructure with further processing on Apache Spark, EC2, or Lambda hardware.
- Azure Event Hubs captures Kafka event streaming data in logs with Azure Blob or Data Lake Storage under subscription plans with an option for CosmosDB used as a keystore.
Streaming Event Frameworks: Persistent Data Storage Plans
Persistent storage is defined by the ability to retain data after the power supply of a device is shut down. Non-volatile storage excludes information that loads in a server’s RAM in sessions or cache storage that may be temporary and regularly refreshed. Most persistent storage is located on hard disk drives (HDDs), solid state drives (SSDs), and magnetic tape drives in data centers. Persistent storage can refer to either file or database storage. The file storage layer of a web/mobile application, and also the production database, is separate from the event streaming layer. APIs and Software-Defined Networking (SDN) are used to securely support microservices with TLS encryption across HTTPS connections in “zero trust” models of cloud governance.
Persistent, Volatile, & Temporary Storage in Event-Driven Software Applications:
- Persistent storage enables the continuation of stateful actors across hardware power-down events, system crashes, or cluster server migrations in files, blocks, and objects.
- Non-volatile persistent storage can be compared to RAM and cache systems which may operate similarly but are not recoverable on power loss or expire after a fixed time.
- Persistent storage in managed cloud event streaming architecture makes available four types of abstraction: Blob storage, Table storage, Queue storage, and File storage.
- The “big data” requirements of event streaming architecture regularly utilize TBs/PBs of storage for platforms with 10 to 20 racks and 18 disk-heavy storage nodes per rack.
- Temporary storage services on managed cloud event streaming infrastructure platforms require an additional layer of off-site hardware configured with SDN for multi-cloud.
For an event streaming architecture, the persistence of database information on a managed cloud platform can be contrasted with temporary storage. While persistent storage systems keep the data on the same platform for reference and access, temporary storage systems only keep the data on the event streaming platform to ensure persistence, whereafter it must be transferred to offsite facilities for warehousing. One of the goals for temporary storage is to lay the foundations for an event-driven architecture that can scale to “infinite” levels. Apache Kafka was built to manage the workload of companies like Facebook, LinkedIn, Netflix, and others whose platforms generate millions of events per second.
Companies managing “big data” warehouses for eCommerce, HPC, or IoT typically prefer to rely on temporary storage when possible due to the reduced complexity and more affordable hardware. That being said, for any use cases that need this data for adding historical context to real-time analytics or for complex analysis at a later time, a persistent storage solution is also needed. Complex software projects generally operate in hybrid or multi-cloud configurations over distributed hardware to optimize persistent storage for production support which includes both event-driven applications and real-time data analytics for any service.
Event-Driven Applications: Connecting Resources via APIs
When evaluating solutions for event streaming architecture, it is important to consider the IT resources and time needed to deliver a usable solution. For enterprises with large data teams, configuring a custom solution with scalable streaming, adequate storage, and real-time analytics is feasible. But for SMBs, building in-house poses a higher risk. Potential misconfigurations of storage infrastructure or insufficient security measures can easily extend timelines and consume budgets.
SMBs can benefit from choosing a managed event streaming platform like Keen that includes persistent storage and allows them to rely on experts for configuration, ongoing operations, and regular maintenance. Keen’s all-in-one event streaming platform addresses the issue of security by using TLS encryption for API connections over HTTPS. All data is securely stored using multi-layer AES encryption. Persistent storage is managed via APIs for I/O transfers with Apache Kafka and integrated data analytics services.
Larger enterprises often choose to build event streaming architecture in-house due to their larger IT departments. There are many open-source and proprietary solutions available that work to manage data storage with public cloud hosting integration for Apache Kafka event streaming architecture. The type of temporary storage used in enterprise-scale event streaming architecture depends on the organization’s requirements and the database adoption. Apache Kafka offers native temporary storage. Other examples of temporary storage solutions for other data architectures include: HostPath, GlusterFS, Ceph, OpenStack Cinder, AWS Elastic Block Store, Fibre Channel, Azure Disk, Azure File, VMware vSphere, and NFS.
Companies using Kubernetes and container virtualization for backend support of in-house Apache Kafka event streaming architecture typically work with enterprise solutions like Portworx and PureStorage. The challenges with persistent storage for event streaming architecture are managed at scale with multi-cluster servers and synchronized replication that must be automated for production in support of platform software. Managed cloud providers like Keen provide zero downtime with rolling upgrades of security patches which can be replicated by CI/CD for teams building DIY solutions. Persistent storage for Apache Kafka event streams hosted in the broker can be up to 10x more expensive for organizations than data lake services.
Solving the Event Streaming Architecture Problem: PaaS/IaaS
Because of the high costs associated with storing Apache Kafka event streaming data at TB/PB scale for real-time processing required by custom software design, Platform-as-a-Service (PaaS) and Infrastructure-as-a-Service (IaaS) products have become a popular solution for SMBs. With PaaS/IaaS products, the managed cloud service provider can either offer long-term persistent storage plans as part of the package plan or provide a limited time temporary storage option with open ended connections to any public cloud or data warehouse service for long-term archiving on hardware. Businesses adopt a variety of SQL, NoSQL, Keystore, and Data Lake solutions for persistent storage depending on the total cost of hardware/software resources and the scale of supported IT operations.
Open source solutions for event streaming architecture and event-driven applications can save organizations money vs. proprietary software but may require a greater spend on trained teams of programmers and engineers to implement. Proprietary software solutions often simplify and quicken the uptake process for businesses. Integrator companies and contractors specialize in building event streaming solutions with different toolsets, i.e. Linux vs. Windows, AWS vs. Google, and Azure, VMware, OpenStack, Kubernetes, etc. for data center support. Much depends on the architecture of the legacy or production software systems and databases that are being supported by the event streaming APIs. Many SMBs are now choosing event streaming architecture as a means to modernize and optimize legacy software for the cloud.
Developing Apache Kafka Event-Driven Applications with IaaS Solutions:
- Complex Event Processing (CEP) allows SMBs and startups to adopt enterprise best practices of companies like Twitter in using Apache Kafka for API, storage, and metrics.
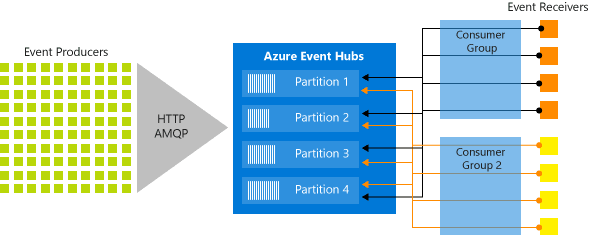
- Azure Event Hubs provides REST APIs with support for ASP.NET, Java, Python, JavaScript, and Go client libraries for publishing events to partitioned storage.
- Stream partitions and tasks can be used to build event stream records into keys using processor topologies to add threaded topics for better fault tolerance in case of failure.
- Amazon SNS allows events to be published for pub-sub messaging requirements and event-driven application support with elastic autoscaling and load balancing on traffic.
- IBM Event Streams supports integrated event streaming in OpenStack data centers using the Red Hat OpenShift Container Platform with Kubernetes container options.
- NetApp offers solutions for managing persistent storage on Amazon Kubernetes Service (AKS) or Azure for high availability, efficiency, durability, backups, and performance.
PaaS/IaaS solutions allow developers to build reactive systems that are flexible, loosely-coupled, and highly scalable. With Stream, developers don’t have to worry about the maintenance of any data center hardware or event streaming software configurations, i.e. deploying, scaling, logging, monitoring, etc. The trade-off is recurring costs due to the monthly or annual subscription model. PaaS solutions make sense for SMBs who have limited DevOps and engineering resources making building in-house especially risky. The challenge of configuring and maintaining a usable event streaming solution with proper storage and analytics is neatly handled by Keen’s all-in-one platform functionality. Rather than creating data infrastructure built on multiple software tools, Keen offers pre-configured event streaming architecture with persistent storage, real-time analytics, and embeddable visualization.
Solving the Storage Problem: Data Analytics & Visualizations
Considerations for building storage and analytics capability into an event streaming architecture is highly dependent on how the infrastructure is implemented. There are a few high-level approaches for implementing event streaming architecture:
- Purchasing a managed Kafka solution and extending it by building storage and analytics functionality
- Buying a complete event streaming solution with options tailored more towards SMBs and others tailored for enterprise-level businesses
- Building and managing event streaming architecture using open-source or cloud suite software in-house.
SMBs often prefer to rely on a managed Apache Kafka-as-a-Service solution like Aiven, InstaClustr, and CloudKarafka. These solutions handle deploying, scaling, and monitoring of the Kafka infrastructure itself, but only offer temporary storage by default. This is not sufficient for applications requiring robust real-time analytics due to the division between recent and historical archives. To solve this, a managed persistent storage solution like Apache Cassandra-as-a-Service is often used along with Managed Kafka. Aiven and InstaClustr also offer Managed Apache Cassandra solutions. Using managed cloud solutions strikes a balance between saving time on managing infrastructure compared to DIY while also having more flexibility in configuration than an all-in-one platform. A notable drawback to consider is that this approach will require more developer resources than an all-in-one platform as well as carry a recurring usage fee, unlike DIY.
Keen’s platform is not just a managed cloud for Apache Kafka service architecture, but also offers data enrichments, stream pre-processing, persistent storage, real-time analytics, and data visualization capability via an API. Another key distinction is that Keen allows users to build upon pre-configured data infrastructure rather than deploying their own Apache Kafka clusters. Kafka Inbound Cluster configurations can be used as an alternative to the HTTP Stream API for integration with legacy systems or cloud hardware according to platform support requirements and expected scale. Retrieval of data for analytics processing is optimized for speed with Cassandra NoSQL.

For in-house development of an event streaming solution, there are a variety of tools to consider as well. IBM Db2 EventStore is used to build event streaming infrastructure support for some of the world’s highest-volume applications, which include web/mobile apps, autonomous driving vehicle navigation systems, IoT devices, and appliance networks. IBM Db2 EventStore specializes in high-speed data stream storage with volume capacity supporting petabytes of information in archives. IBM DB2 EventStore is used with Apache Spark for machine learning on “big data” sets for product/content recommendations and navigation systems. The IBM Event Streaming platform includes components for Data Science, Streams, and BigSQL to power analytics of historical data. IBM Db2 EventStore utilizes Parquet data blocks for persistent storage and SparkSQL for the queries used to generate data analytics from event log archives.
Azure Event Hubs, Event Grid, and other services work with either blob or data lake storage through the Event Hubs Capture framework. Azure Stream Analytics provides real-time search and processing for enterprise software application requirements when generating visualizations or Databricks can be used. Amazon Kinesis Data Analytics allows for Spark, Lambda, EC2, or API processing of data streams in real-time with output to a suite of business intelligence tools. GCP Dataflow offers Spark processing through the Apache Beam SDK as well as BigQuery and BigTable options that integrate with AI processing on TPU hardware. Dataflow also allows developers to build Notebook integration with Google’s AI platform to generate visual analytics.
Get Started for Free! Sign up for a 30 day free trial and get unlimited access to Keen’s event streaming and analytics platform, no credit card required.
Keen: Persistent Storage for Kafka Event-Driven Architecture
Although the individual event message packet data sent over APIs is nominally small, it is the volume of events in streaming platforms that requires a high scale message queue (MQ) framework like Apache Kafka for processing. The world’s most popular websites and mobile applications can generate millions of event messages on their platforms per second in support of user activity. Autonomous driving navigating systems, IoT botnets, and high-performance computing (HPC) projects are a few additional example use cases that utilize Apache Kafka event streaming platform for the processing of “big data” in real-time at terabyte or petabyte scale. In comparison, the event streaming and persistent storage requirements of SMBs for event-driven architectures are often better served by a fully managed platform like Stream.
Keen’s event streaming and analytics platform is based on Apache Kafka with a Cassandra (NoSQL) database for persistent storage of event data. Programming teams can use Keen as a cloud resource for distributed hardware when building event-driven products and applications with real-time analytics. Keen offers a Stream API with SDKs, Kafka connectors, HTML snippets, and inbound webhooks to help developers seamlessly implement real-time, enriched event streams for their product or application. Applications can consume this event data directly from these streams in Stream. It is also possible to further integrate with ksql databases, Materialize, and other API services to build custom, event-driven applications. In addition to the streaming functionality, Keen offers unlimited storage, real-time analytics, and embeddable visualizations for streamed data.
Keen is more affordable, has lower implementation overhead, and a faster time-to-market for Agile programming teams to implement when using our SDKs compared to enterprise streaming platforms like Cloudera and Confluent. When compared to managed Kafka solutions such as Aiven.io, InstaClustr or CloudKarafka, Keen offers the notable advantage of offering a complete event streaming platform with data enrichment, persistent storage, and usable analytics included—no need to build additional solutions on top of your managed Kafka infrastructure.
Learn more about Keen & Apache Kafka Event Streaming Architecture: Read the complete guide Event Streaming and Analytics: Everything a Dev Needs to Know to learn more.


