Here at Keen IO, we often get questions on how to do a variety of things with an event stream. For example, (and these are just a few):
- How can we trigger alerts or notifications based on some pattern of events ingested?
- How can we augment an event with additional properties after it has been sent into a collection?
- How can we generate additional events that might be easier for reporting based on an original event collected?
- After an event has been generated, how can we look at recently occurred events and derive some additional insight that can also be recorded as an event?
Most of these questions have a common underlying theme. The focus is on recognizing that an event has just occurred, and performing some sort of process or function or algorithm for purposes of using that event in a workflow. The workflow could be to drive automated notification to detect errors, as in perhaps a key set of properties is missing or the moving average of events in the past few minutes has dropped indicating a problem. The workflow could also be to generate additional meaning from a particular event through combining the event with other data.
A generic framework to address these questions is based on enabling the streaming of your events collected to S3 and using server-less functions through AWS Lambda. This guide attempts to document the key steps to get started with this approach and (hopefully) some useful blueprints to construct your own Lambda function.
Step 1: Enable S3 Streaming for your Project
Navigate to the Streams section under your Project. This should be a URL of the form https://keen.io/projects/<Project_ID>/streams

You can find more details on the configuration and stream format here, but the process is as easy as specifying the name of a bucket and granting a permission! Within a few minutes, your events, in full form JSON, should start to appear in your S3 bucket. (At Keen IO, we believe strongly that your data is yours and should not require jumping through hoops in order to get it out of your analytics partner.)
Step 2: Define an AWS Lambda function
If you’re new to AWS Lambda, don’t worry. You can head on over to the official documentation to understand how it works.
At its essence, a Lambda is a function that you author which is executed in response to a trigger or according to a schedule, but without the need to provision hardware. The function is server-less, deriving its name from the fundamental concept of an anonymous function in Computer Science.
The first step in creating a new AWS Lambda function is choosing a runtime and a basic blueprint. At the time of writing, you have a choice of NodeJS, Python or Java for the runtime. (Most of our current Lambdas in Production are NodeJS 6.10 or Python 2.7 based)
Once you’ve worked with Lambdas a bit, you can completely dispense with the need to perform the following steps through the AWS Console. As one would imagine, the instantiation of an AWS Lambda function with its associated code and triggers can be completely scripted.
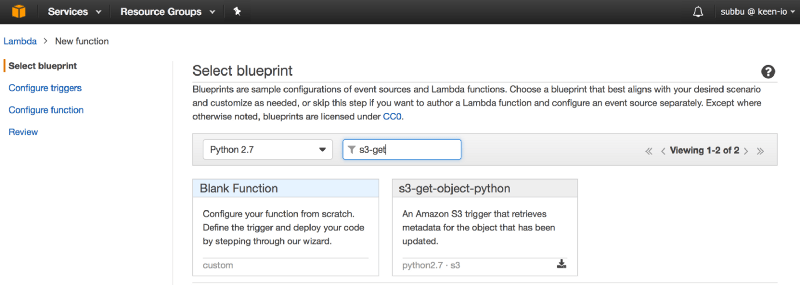
It’s a good idea to write your first Lambda based on a blueprint like the s3-get-object-python as it will give you a feel for the code structure and the parameters passed into the function by the triggering event.
The next step is to configure a trigger for your Lambda function.
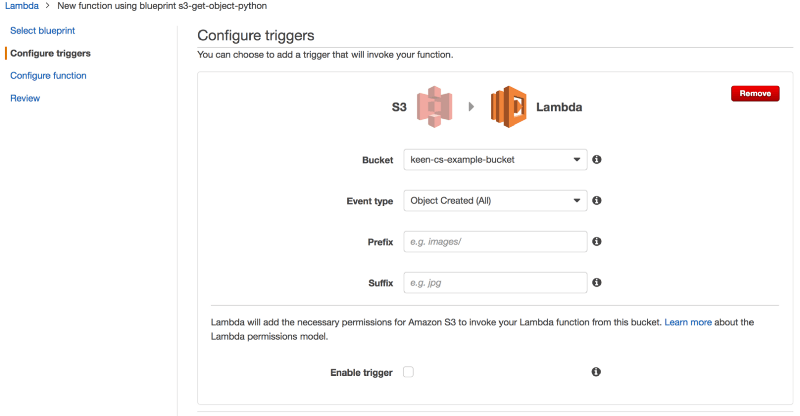
For the purposes of this walkthrough, we’ve chosen to select the S3 bucket where we’re streaming our Keen events to and a simple trigger that says “Object Created (All)”. This is like saying “Run this Lambda function any time a new object is created in this S3 bucket”.
If you have multiple Projects streaming into the same bucket, you could specify the Project ID as a prefix, so that the Lambda function is triggered only for events within a particular Project.
The key step in defining the Lambda function is giving it a name and the actual code for the function you would like to run.
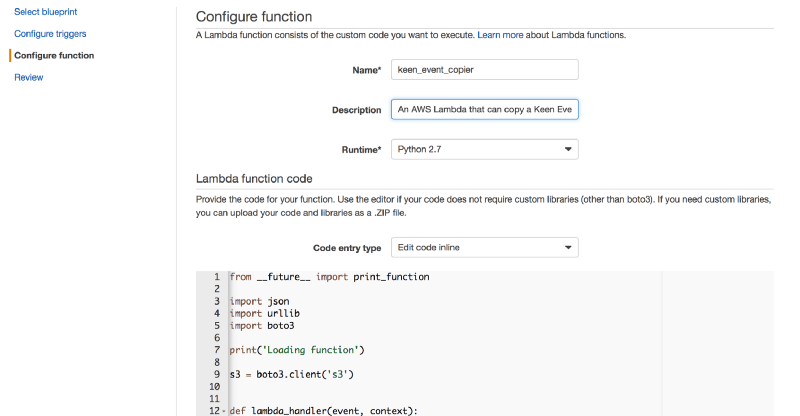
The example here shows a Lambda function named keen_event_copier, presumably a function that will generate a copy of a Keen event from the S3 stream.
While it is possible to have a fairly trivial Lambda function directly written inline, any Lambda that uses additional libraries needs to be assembled into an archive containing all the required dependencies and uploaded to AWS. Our Lambda, at a minimum will use Keen’s Python SDK in order to send events to a different Project, so we will need to create an archive and upload the function. We’ll get to this shortly, lets finish the last bits of the Lambda definition.
We’ve given the Lambda a name, which is equivalent to the filename within which the Lambda is defined. The Handler specifies the actual (Python) method in our case, and similar for other runtimes, that will be the entry point for our Lambda. By saying keen_event_copier.lambda_handler as our Handler, we’re effectively pointing to a method called lambda_handler within the file keen_event_copier.py as the place where our Lambda should start executing when the trigger is fired.
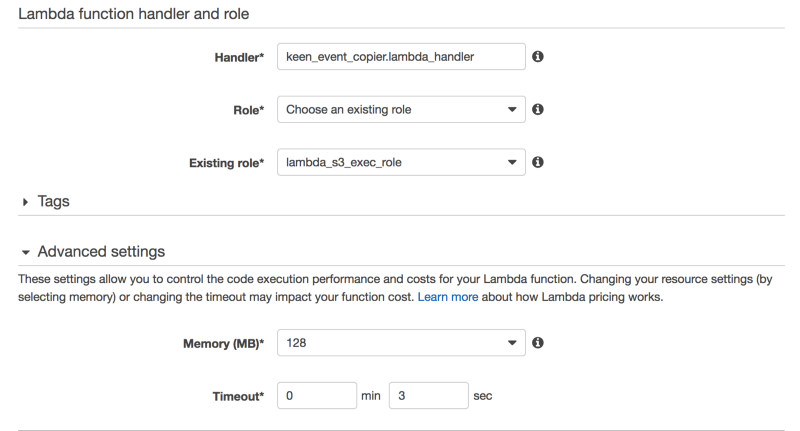
We need a few more settings, including a Role that has privileges for executing a Lambda and the Memory allocated to our Lambda as well as how long the Lambda can run before stopping.
A key thing to note here is that Memory is limited to 1536 MB and the runtime is limited to 5 minutes. But there is a lot that can be done in 5 minutes!
Step 3: Writing the code for the Lambda
The entirety of the Lambda function follows. There are plenty of efficient ways to do the same thing, and my Python is only marginally better than my Esperanto, but I wanted to share a few details in a slightly more verbose manner, hence the code below.
from __future__ import print_function
import boto3
import botocore
import zlib
import json
import copy
import keen
import urllib
BUCKET_NAME = "keen-cs-example-bucket"
TARGET_PROJECT_ID = "<>";
TARGET_PROJECT_WRITE_KEY = '<>';
s3_client = boto3.client('s3')
keen.project_id = TARGET_PROJECT_ID
keen.write_key = TARGET_PROJECT_WRITE_KEY
def read_s3_object_into_json_list(s3_object):
# Read the compressed file contents into a String
s3_file_contents = s3_object['Body'].read()
# The second argument is needed in order to skip the GZIP Header
s3_uncompressed_file_contents = zlib.decompress(s3_file_contents, 16+zlib.MAX_WBITS)
# Generate an array out of the file contents - newline delimited events
events = s3_uncompressed_file_contents.split("\n")
json_events = []
for e in events:
json_events.append(json.loads(e))
return(json_events)
def lambda_handler(event, context):
# These are for an S3-driven lambda
bucket = event['Records'][0]['s3']['bucket']['name']
key = urllib.unquote_plus(event['Records'][0]['s3']['object']['key'])
s3_object = s3_client.get_object(Bucket=bucket, Key=key)
if s3_object != None:
collection = s3_object['Metadata']['collection']
print("Processing Events in Collection %s" % collection)
collection_events = read_s3_object_into_json_list(s3_object)
num_collection_events = len(collection_events)
print("Number of collection events %d" % num_collection_events)
n = 0
for e in collection_events:
c = copy.deepcopy(e)
# Remove keen['id'] and keen['timestamp'] from the event
del c['keen']['id']
del c['keen']['created_at']
# Add an additional property indicating the S3 file that was the source of the event
c['S3Object'] = {}
c['S3Object']['URI'] = "s3://" + bucket + "/" + key
# Publish to the new Keen Project
keen.add_event(collection, c)
n += 1
print("Number of collection events processed %d" % n)
- Remember
lambda_handeris our overall entry point. The second method is just illustrative to confirm that you can write logical and normal Python as you might even in the confines of a Lambda. - The S3 Object trigger provides two parameters, ‘event’ and ‘context’ from which the actual full S3 bucket and key can be constructed. The complete ‘path’ is needed in order to read the contents through
s3_client.get_object(). - When Keen streams your events to an S3 file, we include an S3 Metadata header property indicating what event Collection this file belongs to. So you don’t need to parse the S3 location in order to figure this out.
- Keen’s S3 streams are gzipped by default, so a quick call to zlib is required to decompress the S3 object’s contents. (Notice the second parameter in
zlib.decompress()to get past the normal gzip header) - The Python version here generates a list of event dictionary objects from the S3 file. The more optimal approach here would be to operate more as stream with line emitter, particularly with NodeJS, so that events can be asynchronously extracted from the streamed file and operated upon.
- The
copy.deepcopy()is an approach to clone the complete event which could have many nested JSON properties. One of the advantages with Keen events tends to be the extremely flexible schema with logically nested JSON representing different parts of an overall event body. A copy is not completely necessary but ensures that in case we need to perform some form of difference determination between the original event and the new one we’re going to generate, we preserve the original. We do need to delete the keen generated ‘id’ and ‘created_at’ fields at a minimum before we publish our new event. - We have previously specified the target Project ID and Write Key for the Keen client, so the
keen.add_event()will now send this event to a new Project in a collection of the same name as the original.
We’re now ready (after some local testing of course!) to package the Lambda and upload it. This does require that the Lambda package contain all the libraries necessary for it to run, implying that all the imports at the top need to be packaged with the handler itself.
One way to do this is to use pip.
pip install package_name -t folder_containing_your_handlerAs the AWS Lambda documentation for Python specifies, any package other than boto3 will need it installed locally. After this you’re ready to zip up the contents of the directory and upload the archive in place of editing the Lambda code inline.
(A word of caution, the Archive should contain the contents of your folder in which you have the handler and other libraries directly at the top level of the Archive, and not /<folder>/<handler_name>.py inside the Archive)
A command line alternative to performing all these point and click steps is to use the AWS CLI to create a Lambda. For example,
aws lambda create-function \ — region <aws-region> \ — function-name keen_event_copier \ — zip-file fileb://<archive>.zip \ — role <iam:arn:identifier>/lambda_s3_exec_role \ — handler keen_event_copier.lambda_handler \ — runtime python2.7 \ — profile default \ — timeout 300 \ — memory-size 1024
You may have noticed that the trigger is missing. For that, you would need to set the lambda_function_configurations() as part of a BucketNotification. A good place to look at how to do this with the AWS Python SDK is here.
Step 4: Monitor your Lambda function in AWS Cloudwatch
Every execution of your AWS Lambda is monitored in Cloudwatch, and all your print() statements in the Lambda code will appear as Cloudwatch logs.
Now, lets get back to the original question of this guide.
With a triggered function setup that listens for Keen’s stream into your S3 bucket and the necessary foundation to consume full-form JSON events, any of the questions that were asked at the beginning simply require one or more methods that can take the event body and do something with!
Transformation Example
For example, a recursive look into the event structure and transformation of a property into something else can be accomplished through a method as follows
def traverse_and_transform_dictionary(d):
for k,v in d.items():
if isinstance(v, list) and len(v) > 0:
# If we have an array and want to expand it
# or perform some computation on the array elements
if isinstance(v, dict):
traverse_and_transform_dictionary(v)
With the ability to traverse the event model in the Lambda, any number of transformations are now possible. You could change datatypes in the cloned event, you could add new properties that are calculated from others in the original event, and you could perform a lookup and replace an id with a more meaningful name in the event.
Attribution Lookback Example
Another example is to look back for attribution purposes. Keen’s S3 stream file also contains a Metadata attribute for timestamp. In this snippet, we use the Arrow Python library to generate timestamps for each interval of 5 minutes that we would go back and read.
s3_file_timestamp_str = s3_object[‘Metadata’][‘timestamp’]# Convert into date time s3_file_timestamp = arrow.get(s3_file_timestamp_str)# Default Keen Streaming Interval STREAMING_INTERVAL = 5 # Go back 20 minutes or 4 Intervals of 5 minutes each NUM_LOOKBACK_INTERVALS_DESIRED = 4lookback_intervals = []for i in range(NUM_LOOKBACK_INTERVALS_DESIRED): # Generate a timestamp for each interval lookback_intervals.append(s3_file_timestamp.replace(minutes=-i*STREAMING_INTERVAL))
Now that the intervals have been generated, we can easily generate an S3 key to read a Keen S3 stream file and process it to find correlation between events that occurred in the 20 minutes prior.
def generate_s3_bucket_key(collection_name, interval):
interval_iso_zulu_format = interval.isoformat().replace(“+00:00”, “.000Z”)
key = KEEN_PROJECT_ID + “-” + collection_name + “-” + interval_iso_zulu_format + “.json.gz”
key_with_path = KEEN_PROJECT_ID + “/” + interval_iso_zulu_format + “/” + collection_name + “/” + key
return(key_with_path)Having generated a set of look-back intervals, the actual attribution logic could involve reading the events within these intervals and performing some custom function on those events to determine a degree of attribution between what occurred before and the current event being considered.
Other patterns include reading from Keen itself, say a count query over the past hour, or a reference look into a DynamoDB instance or a Redis cache and add properties to the copied event to be sent into another collection.
And let’s not forget, we can also use the Lambda to post to your favorite Slack channel for a simple alert or trigger a push notification through SNS or anything else that sends a message into your desired workflow.
The Power of Streaming Full-form Event Data
It is often easy to send event data to a platform. But once its there, how do you use it easily? How do you act on events? How do you funnel the events into a custom function that feeds into a unique workflow?
With many platforms, the barrier is often easy and timely access to the raw data. Sometimes the data needs to be extracted into CSV or a request needs to be made to support or you need a series of batch jobs to work with the data that is collected, which is after all your data! We believe that the timely streaming of full-form events as JSON into S3 along with easy-to-deploy blueprints based on Lambda make for a powerful combination and open up a lot of possibilities.
If you have questions or get stuck, please head over to https://keen.chat and drop us a note mentioning this guide. We’re here to help.


