An old boss of mine had a phrase he used whenever shit hit the fan. You know, those special and sometimes amazing circumstances that inevitably happen when you’re trying to run a bunch of computers toward a common goal. He was fond of saying: “opportunities arise”.
This summer at Keen IO, we a had a series of postmortem-worthy “opportunities” that threatened everything we hold near and dear: the stability of our platform, the trust of our customers, and the sanity of our team. Please allow us to tell you about them in cathartic detail.
Opportunity Knocks and It’s a Closet And It’s Full…
The morning of July 21st, I was working from home, because I had a flight to O’Reilly’s OSCON later that day. With some time to kill, I was looking over various charts and alerts for our infrastructure, when I noticed there was a muted alert that had been triggered. We generally mute alerts when we don’t want to be bugged with an email or a phone call temporarily. Unfortunately, this alert had been forgotten, and it just so happened to be one of the most dreaded in all of computerdom:
The filesystem on kafka-0000 is nearly full! (87%)
Oh, shit. I mean, uhm, what a great opportunity!
That’s quite an odd error to see! Kafka is a distributed log. At Keen, we write incoming events to Kafka as a sort of holding tank until we can write them into Cassandra for permanent storage. Kafka is configured to retain a rolling 168 hours — as some people call it, a week — of data just in case we need to refer back to it. The significance of this error was that we no longer had enough space to accommodate a week of customer data! How did this happen?
The Source of Opportunity
After reaching out to some teammates, I learned that one of our customers had released a new mobile game over the weekend that been a great success. Awesome! The downside was that the huge wave of inbound data from that game was exceeding our short-term storage.
We needed to get this worked out fast, but our options were limited. See, the version of Kafka we were using at the time — 0.7.x — didn’t allow you to change retention configuration without restarting. We couldn’t do a restart due to a lack of replication; again a Kafka 0.7.x thing. If the disks filled up without a fix, we’d have to stop accepting new events!
We very quickly (and under some serious pressure) came up with a clever work-around: we wrote a short Python script that changed the created time of the oldest Kafka log files to a date outside of the rolling window. Kafka dutifully deleted the files for us afterward!
Feeling very smart and very clever, we patted ourselves on the backs and sighed a big breath of relief. Phew! Our immediate disk shortage problem was resolved.
Little did we know, this was just the first shot in a scalability war that was to consume our platform team for the the next 3 weeks.
See, while we were bailing water, not only did large volumes of data continue to flood in. The rate of data coming in continued to increase. Here’s what it looked like in terms of bandwidth used:
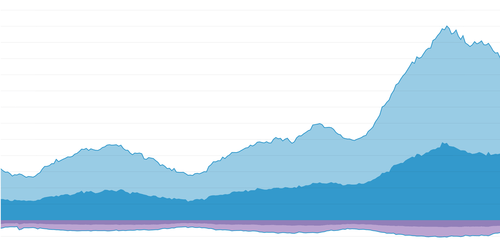
Here’s what it felt like:

* Not to be confused with “awkward moment seal”, this is his sister, “oh god what is happening to our platform” seal.
The Opportunity Fix
While beginning to plan for a Kafka upgrade, which would help with our scalability, we were hit with another setback: We started getting warnings that we were not writing data fast enough. Deep queues began to form because our “write path” was completely overwhelmed.
We spent an entire day firefighting and tuning this issue, and while we made a lot of progress, we eventually started to realize we might not be able to keep up.
We got on the phone with our customer and put our heads together. Turns out, while this was a big, important game launch, it wasn’t the biggest game launch in all of history — this particular game was quite heavily instrumented and sending a disproportionate amount of data. Even nastier, some of appeared to be junky duplicate data. In an effort to keep up with the incoming flood, and ensure we captured the most important events, we identified some data types that we could start dropping, like every time the app was brought to the foreground or background.
This release valve gave us room to breathe and begin a further investigation, but we started to feel a little bit ill. Usually, when our customers send lots of data, it’s a good thing. Gaming companies run their businesses on the data they store in Keen IO. The last thing we want during a big game launch is to decide what data not to keep — that’s not something we’ve ever had to do here at Keen IO. This incident was just as terrifying for our customer as it was for us. It was awful.
AND, even after all the progress we’d made, and even though we stopped recording some events, the inflow of data was growing and growing. What was previously our monthly data volume was now our DAILY data volume. It looked like this:
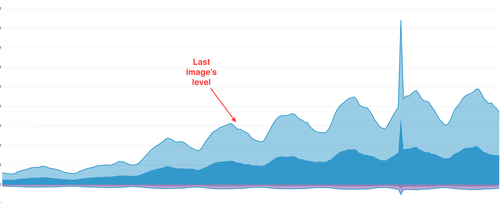
Though we didn’t know it, by this time, we’d already committed one of our biggest mistakes (and it was not a technical one). While we focused on keeping our platform alive, we told our customer to figure out why their game was sending orders of magnitude more data than any game launch ever. At the time, it seemed reasonable. We’re collecting data for lots of apps, what’s wrong with yours!? (huge retrospective cringe)
While we hoped our customer would figure out why their app was going berserk (and also began doing a bit of our own snooping around the client), the data kept pouring in. Now the volume was more terrifying than ever! We’re used to lots of data coming into Keen IO. When particularly big and unexpected waves come in, it slows down our write time, which is what we’d been battling up until now.
At this point, though, we were seeing a new and more dire challenge. We were getting so many requests that it threatened the stability of our load balancers. If the load balancers go down, we can’t handle new requests, and customer data spills out into the ether, never to be recovered. Now, as opportunities go, this would be a pretty terrifying one. It might even warrant ditching this whole “opportunity” joke and actually calling it a problem!
Thankfully, mercifully, some new information surfaced at just the right time.
We received an email from the customer noting that they’d inspected the HTTP response from a batch POST of events, and that they didn’t see the normal acknowledgement of write failure they were expecting. Thunderclaps echoed around the office as we slapped ourselves on the foreheads.
Turns out, our previous awesome fixes were actually causing bad payloads to be retried over and over again, each time amplified with a little more data. That’s right: by blocking some events, we’d commanded hundreds of thousands of devices, all over the world, to repeatedly try sending us an increasingly large payload. You couldn’t plan a better DDoS.
We paused a few seconds to let that sink in.
http://giphy.com/embed/zkoJDFRCE1lpC
Minutes later, we pushed out a change that correctly acknowledged the messages we were dropping. The effects were immediate.
The Opportunity Fix’s Fix
There was a pretty sharp decline in bandwidth consumed when we shipped this fix:
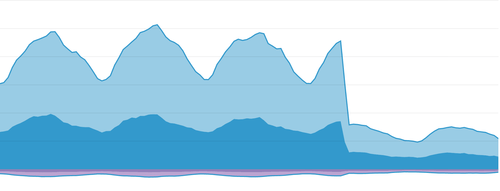
In our excitement to have isolated such a significant problem, it took us a few days to note that despite the changes, we were still seeing day-over-day increases. While our load balancers were handling the traffic well, it was a hint that something was still amiss.

The Fix for the Opportunity Fix’s Fix
And so we soldiered on. Dan dug in on planes (and trains!) during his family vacation. Kevin developed a healthy addiction to the game (and its log files) while attending a wedding. Michelle’s family openly questioned if she was working too much.
While our customer scoured the game code for clues, we dug into the Android SDK, the incoming data patterns, and, finally, some interesting HTTP response captures they sent over.
That little HTTP capture, which we almost dismissed, finally pointed at the source of that never-ending stream of data. Well. This is quite an opportunity we’ve created for ourselves.
Turns out, there was an edge-case scenario, a bug, in our API (not in the client!). A malformed event (a “poison pill”) would cause some of the events in a batch request to be written to our database, but then the entire request would fail (i.e. a 400 response code) and all events in it would be retried. The reason this game was impacted more than any other was that it happened to generate null events on some devices, effectively poisoning them and turning them into little warriors in our self-inflicted DDoS.
We deployed a fix for the poison pill right away and saw a huge improvement immediately.
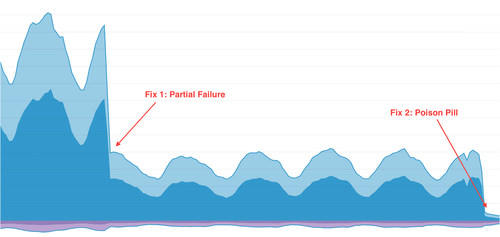
Relief. Relief!

What We Learned
We added a lot of safeguards and (re)learned a few lessons after this series of events. Let’s look them over specifically.
Our file system monitoring is now correctly unmuted. Oops.
Customers are a vital source for debugging information. Our users are amazingly smart and their help was essential! Moreover, it’s really important not to assume it’s the customer’s fault!
Remember to think outside ye olde box. Many of the clues we got came from places we weren’t expecting and sources we didn’t think were related!
We’ve added an extensive amount of monitoring to our API layer to detect anomalies such as failed events and other problems. We’ve been monitoring and tuning the alerts that use this over the last few months.
We upgraded to a newer version of Kafka with replication and other awesome things. While this wasn’t directly related it did factor in to some of our early pains. We’re now running Kafka 0.8.x with replication and a lot more storage.
Using time-based bounds for space-limited things can be bad. You also need space-based bounds on these things as well as a fallback to prevent filling up the disk!
We are in the process of a comprehensive rethink of retry logic in our mobile SDKs. There’s a tricky question — with hints of the Two Generals’ Problem — at the heart of this design choice: if a mobile device sends an event to the server but isn’t sure if it made it or not, does it err on the side of retrying until it’s sure or on the side of deleting the event and avoiding duplication? Prior to this incident we had assumed the former, but we now realize that a more nuanced answer is mandatory.
Overall we really beefed up historical metrics, monitoring and awareness of some key parts of our service. It’s a good reminder that this isn’t something you’re ever really “done” with and such things need to be considered for every deploy and rollout you do. Automating this is essential!
We survived! It’s amazing what you’ll learn under pressure. In the month prior to this event, we made the difficult decision to not take on a new, large customer. They wanted to send us what we perceived as a HUGE data volume, and it was scary. Then this wonderful opportunity happened and we didn’t have a choice: HUGE data invited itself in!! In the middle of it, we upgraded Kafka, tweaked a zillion layers of our stack, added hardware, and came out of it with significantly more capacity — a process we thought would take months to achieve. We also survived a DDoS without any data loss. At the end of it we looked back in shock, mortified by our mistakes but also amazed at what we’d pulled off.
We take our responsibilities to our customers seriously. This is the first time at Keen IO where saw first-hand how our mistakes impacted a customer in a real, tangible, and important way. It was an incredibly humbling and maturing time for our team. We continue to be amazed at the patience and understanding their engineers have shown in working with us, and have a profound appreciation for them.
Closing
Fine. I’ll admit it. Despite the repeated jokes these situations really are opportunities. Looking over this list of accomplishments showed how much we gained in terms of knowledge, capacity and camaraderie. It’s really hard to see that when you’re in the thick of it, but it’s pretty plain in hindsight.
So wherever you are, old boss of mine with your “opportunities”, I apologize for scoffing at your opportunity talk and your indefatigable optimism, and also for that time I set your desktop wallpaper to a screenshot of your desktop and hid all the icons. Maybe you were right after all.


