On Friday, July 19th, we experienced a rolling outage from approximately 2:42 AM PDT until 5:44 AM PDT. This is the first (and therefore most significant) downtime we’ve ever had. I’m going to explain what happened, how we looked into the problem, the steps we’ve taken to resolve the issue, and what we’re going to do next. This will be a technical deep-dive — if you’d prefer a more literary approach, I’m working on a blog post that describes what it was like to discover this problem (and fix it).
Prerequisites
Before we begin, allow me to share some required information about our technology stack and deployment. Our API servers run in Python on top of a web framework called Tornado. Its main claim to fame is that it’s an asynchronous web framework using non-blocking I/O. There’s a lot to learn about Tornado, but for purposes of this RCA, the only required concept to understand is that Tornado runs on something called an event loop. Think of Tornado like node.js, except for Python.
To oversimplify a ton, what this means is that Tornado will only ever run one piece of code at a time, with the huge exception of doing non-blocking I/O — Tornado can do basically as many non-blocking I/O operations at once. More concretely, this means reading from and writing to HTTP streams can be parallelized (which is how Tornado can effectively solve the C10K problem). It also means that if you have any blocking code which takes a long time to execute, that code will block Tornado from doing anything else.
We run multiple instances of Tornado (multiple machines and multiple processes per machine). We do this to (a) distribute load across multiple machines and (b) decrease the likelihood of one Tornado server getting into a “bad state” from affecting our users.
Keen IO API requests come into a server running nginx as a reverse proxy (aka our load balancer), which then handles distributing the requests to our backend Tornado API servers..
What Happened
At approximately 2:42 AM PDT, a customer sent us a particular kind of query. They asked us for what we call a Series with a Group By. What this means is the query result is going to include a list of time intervals, where each interval itself has a list of results which are grouped by the requested parameter.
Tornado handled reading the request and querying the database with no problems. The customer has a small dataset and the database processed the query efficiently and quickly. Database queries are done via non-blocking I/O, so Tornado hummed without complaint.
One very common task with any application that reads from a database is how to transform the result from a database query into something useful for the consumer of that query. In our case, we do a number of transformations, or post-processing, of the database query results into our JSON API result. The outage yesterday revealed a big problem in one of the ways we post-process query results.
One of the things we take pride in here at Keen IO is that we try to make complicated problems more simple and we try to make annoyings things pain free. A Series with a Group By Query has a potentially very annoying problem. Let me try to illustrate it.
Here’s an example result returned by our API (on the left):
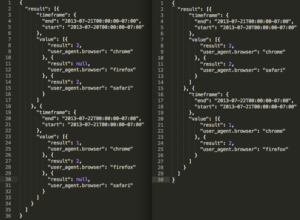
Here we’ve got two time intervals (daily ones), with each interval having results that are grouped by a property called “user_agent.browser”. Note that in each interval, one of the browsers has a null result (I’ve bolded them). This is done by our post-processing. The result from the database doesn’t include a value for properties which have not appeared in a particular time interval. So the database result would look something like the right side of the above image (note that the null values have disappeared).
The problem is that this is annoying to deal with on the client side. Most likely a user is going to want to visualize these results in some way — likely in a multi-line or multi-bar chart. But if the value for one of those lines (i.e. one of the user agents) doesn’t even exist for one of the time intervals, a lot of visualization libraries will error out saying they don’t know how to deal with the bad data.
Our post-processing exists to find these missing values and fill them in with NULL before we give a result back to our users. We think it makes their lives a lot better.
This post-processing is done in-line in Python code as part of the HTTP request that’s processed by Tornado. It’s blocking code (you can probably guess what’s coming). For “normal” queries, this is basically instantaneous and unnoticeable by users. But this particular query was a degenerate case where there were thousands of groupings.
The algorithm we use for this post-processing is inefficient and breaks down for a large number of groupings. Instead of happening essentially instantly, it took (wait for it) just about three hours of blocking time to run. Here’s a lovely chart from New Relic from one of our app servers:
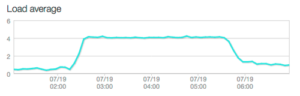
That’s obviously no good. But some of you may be wondering how this could result in an outage. After all, we’ve got multiple API servers each running multiple Tornado processes. Wouldn’t other traffic be served by these?
The answer, of course, is yes. Except (there’s always an exception in these things, right?) that nginx has a great feature for reverse proxying called proxy_next_upstream. In non-technical lingo, that basically means you can configure when nginx decides to retry a particular HTTP request on another server. Our load balancer was configured with a value of “timeout” for this setting. Here’s what happens with that setting:
- An HTTP request comes in from a user to the load balancer.
- Nginx sends that request off to an API server for processing.
- If the API server takes a long time to process (say, 10 minutes), Nginx will say, “Okay, that server’s clearly dead, let me retry this request on another API server.”
- Nginx sends the request to another API server.
Normally, this works perfectly and handles the case when an API server becomes temporarily unavailable (i.e. hardware failure). Nginx will route around the failure for a while and our users won’t know anything bad happened. Unless, of course, an HTTP request can cause an API server to become unavailable (as was the case here). Here’s what happened to us on Friday:
- Query of Death hits load balancer.
- Load balancer sends request to API server.
- API server runs query and starts churning on post-processing.
- Load balancer times out the request before it can be finished by the API server.
- Load balancer sends Query of Death to the next API server in the pool.
- Repeat steps 3–5 UNTIL
- There are no more API servers for the load balancer to try.
- Load balancer rejects incoming API requests until one of the API servers come back (as they did).
That’s what caused the outage.
The outage was considerably longer than it should have been because our alerting failed to wake anybody on our team. This is due entirely to human error — we ran out of credits on the service we use for alerting (Pingdom). There’s no excuse here.
To make matters worse, there’s no status page to see what’s going on with the Keen IO API. Our customers were in the dark for this outage.
Let me recap the problems really quickly:
- Our load balancer had a bad configuration value.
- Our API code had a bug that, for certain types of queries, could result in blocking code running for a really long time.
- Our alerting system failed because we didn’t have any credits.
- Our customers didn’t know what was going on because we have no status page.
How We Fixed It
The first thing we did was change the proxy_next_upstream value in our nginx configuration from “timeout” to “error”. This prevents bad HTTP requests from propagating to all API servers while still making sure hardware failures, network outages, or other service interruptions are handled with no disruption from our customers’ perspective. It’s completely unacceptable for one user to be able to affect our overall service and this setting change assures that this particular type of problem won’t occur again.
Next, we looked into the post-processing code I described above. We’ve mitigated the risk it raises in two ways:
- It’s been moved to execute in another process. Code running in another Python process doesn’t block the Tornado event loop, so other API requests will continue to process.
- We added a short-circuit to the algorithm. When a degenerate query like this comes in, we won’t attempt to post-process.
Even better, this code goes away completely with our new architecture. The new system is on the cusp of being rolled out to all users, but we’re not there yet. Stay tuned for a blog post talking about what’s coming in much more detail.
In the process of diagnosing and fixing this issue, we also noticed a potential problem with JSON serialization taking a long time. By default, we pretty-printed JSON results. That’s fine for small results (as most of our queries are), but for really large results, pretty-printing JSON isn’t free. We’ve fixed this by turning pretty-printing off by default, and including a parameter to turn it back on optionally.
We’ve added credits to our Pingdom account (and turned on auto-filling so that this can never happen again).
We don’t have a status page (yet).
What’s Next
Hopefully, I’ve made it clear that we found some obvious problems that, in tandem, caused the outage. And, hopefully, you can see that we fixed all of them quickly. We have had no service issues since Friday morning.
That being said, it’s important to examine the underlying issues here. A bad load balancer configuration combined with an application bug is one layer, but if you dig deeper, it becomes obvious that there’s an architecture level decision that we need to change.
We think it makes sense to have a logical separation between the infrastructure that handles writes (i.e. saving events to Keen IO) and handles reads (i.e. doing queries in Keen IO). Neither should ever go down, but our customers have made it clear that it’s essential that writes should proceed normally even if reads are degraded in some way. We’ll be taking steps to get to that point.
That work is now at the top of my priority list. It’s mostly about ensuring that we have dedicated Tornado servers for writes and dedicated Tornado servers for reads. This work is not done yet (only a few days after the outage at the time of writing), but it will be done soon.
We’ll also be rolling out a status page. If you have any suggestions on a service or product to use to get us there faster, please let me know!
Final Recap
- Problem: Our load balancer had a configuration that meant bad queries could propagate to every API server, making every API server unreachable at the same time.
Solution: Change the load balancer configuration to retry queries only when an infrastructure-level error occurs. - Problem: Our API server was doing a bunch of post-processing to a query result in a blocking fashion.
Solution: Move the post-processing to an asynchronous background process AND cut down the amount of time it can execute to a reasonable limit. - Problem: Our alerting system failed because we didn’t have any credits for alerts (entirely our fault).
Solution: We’ve paid for more credits now and enabled auto-refilling on our account so this can’t happen again. - Problem: We didn’t have a status page to tell our users what was going on.
Solution: We’re actively working on getting a status page up for our users.
Summary
This incident has served as a clearly needed reminder of our obligation to our customers. This outage is completely unacceptable. The whole reason our company exists is to transform the complexities of building large-scale analytics infrastructure into an easy to use product that our users can trust. Obviously this is a step back for that trust.
My hope is this detailed post explains both what happened from a technical perspective and shows how seriously we take this. Any downtime is unacceptable. If it does happen, our obligation to our users is to be completely transparent about what caused the issue, so they can make informed decisions about using our products.
Please feel free to reach out to our team, leave a comment below, or e-mail me directly if you have any questions, comments, or concerns. I’d be happy to go into more detail on anything here.


