This article was originally published in June 2013 and has been updated.
There’s this new and really powerful type of data: event data. Well, it’s not really new. I bet you are already familiar with event data, even if you don’t know it by that name.
Event Data is Everywhere
Events are happening all around us. In our apps, cars, appliances, servers, and even in our brains. This is a very exciting time because we can now collect and analyze events at massive scale. More and more things are becoming internet-connected, making it easier to collect data from all sorts of places. What discoveries will we make about our apps, our behaviors, our society, and ourselves?
I’ll leave that question open and focus on an easier one for now. What is event data?
Entity Data
The easiest way to learn the concept of event data is to compare it to another type of data: entity data. If you’ve ever worked with an application database, or an excel spreadsheet, you know about entity data. Entity data looks like this:
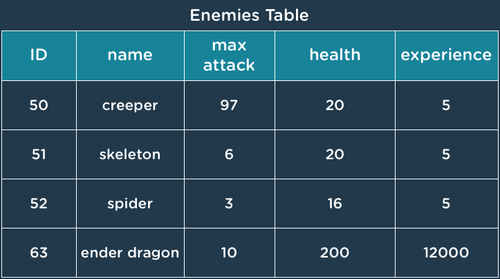
Entity Table Example (Enemies Table)
Entity data is stored in tables. Entities are things like users, products, accounts, posts, levels, etc. There is a separate table for each of type of entity, and each table has columns to hold properties about the entities. There is one row in the table for each entity. In this example, the entities are enemies.
Most databases have been designed to store entity data. They’re sometimes referred to as relational databases.
Entity data is really good for capturing the current state of your application. Things like users, number of each type of product, accounts payable, etc. You can very quickly lookup information about any entity.
One characteristic of entity databases is that they are normalized. Data is rarely duplicated. For example, you might have a table for Accounts, with attributes like the account name, type, category, etc. Accounts have many users associated with them, but you wouldn’t store information about those users in the Accounts table. Instead, you would include a key in each user record which links to its account. From a data storage (disk usage) perspective, this is very efficient.

Entity data example from the excellent Wikipedia article on joins
One drawback to this data model is that in order to run analysis on the entities, for example, sort employees by department name, you must pull in data from multiple tables. At large scale, these operations take time.
Event Data
Now let’s look at the characteristics of the new data type, event data.

Event data example: “publish” event
Event data doesn’t just describe entities; it describes actions performed by entities. This example above describes the action of publishing this blog post. You can imagine we have a collection of events called “publishes” where we track an event for each new post.
What makes this publish data “event data”? Event data has three key pieces of information. I first saw these identified by Ben Johnson in his speakerdeck on Event Data (he calls it “Behavior Data”).
1. Action
2. Timestamp
3. State
The action is the thing that’s happening (e.g. “publish”). The timestamp is self explanatory: the point in time the thing happened. The state refers to all of the other relevant information we know about this event, including information about entities related to the event, such as the author.
Let’s look at a more complex event. This is a “death” type event:
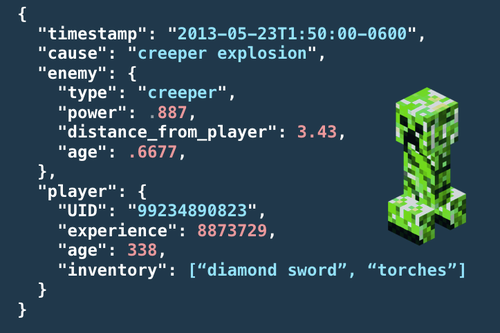
Event data example: minecraft death event
Here is an example data point for a player death in the game minecraft. Imagine we are recording every player death that happens in the game.
If you haven’t played minecraft before, all you need to know is that it’s amazing and, similar to many video games, there are a lot of ways in which the player can experience death: falling from great heights, starvation from not eating enough pork chops, drowning, clumsily stumbling into lava, zombies scaring the crap out of you in a cave, etc.
Let’s say we want to analyze these player deaths in Minecraft. Perhaps we want to find out the most common type of death, the average player age at the time of death, the most lethal enemies, or any number of death-related questions. Perhaps we are trying to find out if the game is too difficult on certain levels, or if the new villain we introduced is causing way more destruction than we’d imagined, or if there is any correlation between types of users and types or frequency of deaths.
We can find out all of these things using the simple event data model shown above. The event data model has a few special qualities:
1. The data is rich
2. The data is denormalized
3. The data is nested
4. The data is schemaless
Event Data is Rich
This death event has a lot of properties — information about the player at the time of death, the cause of death, the enemy. Events can have hundreds of properties; they seek to describe not just one entity, but all of the entities involved in an action.
In fact, I think we should add even more data to the Minecraft death example. Information like: location of the death, game settings, and software version. Can you think of more?

Perhaps we’ll discover that players on difficulty level “hard” experience death by skeletons at a rate of 10x those on “normal” difficulty. Is it just me or does that skeleton look extremely smug?
Event Data is Denormalized
Unlike a relational database, you see the same data repeated over and over again in an event database. Things like user attributes, app version, or difficulty settings might be repeated on every single event, even if they rarely change. Although it’s not super intuitive (and downright unnerving to SQL veterans), this redundancy is the only way to capture a representation of the application state at the time of the event. Contrast this with relational (entity) databases. In entity databases, properties (e.g. player settings) are updated and the previous values are lost forever. Event databases give us the ability to capture that entity data at a point in time. Event databases are not an alternative to entity databases. An event database is a great companion to an entity database.
Event Data is Nested
Event data can have lots and lots of properties; most databases optimized for event data allow you to store it using nested JSON. This is really helpful when you have many properties and multiple entities to describe.

Event Data is Schemaless
As we discussed, event data allows you to capture state at the time of an event. But different properties will be important for different types of minecraft deaths. For example, starvation, drowning, or lava deaths don’t involve an “enemy” and might have their own unique properties like lava temperature. In other words, the death events don’t follow a strict schema. We’ll add or remove data depending on the type of death. Event databases are designed to handle any number of arbitrary properties that you send.
Event Data at Scale
Minecraft is a huge game. 11 million people have bought the game and they are still selling over 10,000 downloads per day! That’s a lot of user records. Consider the volume of event data points compared to entity data points. For every one user there are many actions.
Entity data captures the current state of things. Event data captures the history of actions that happen over time. Event data happens at a much greater scale than entity data.
Thankfully, we are now in an era where data storage is cheap enough that it’s possible to store event data in a cost effective way. Plus, there are all sorts of tools and cloud services that make tracking this type of data easier than ever.
Summary
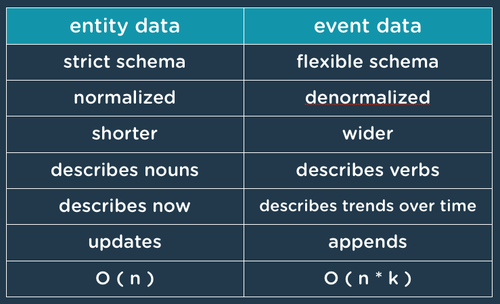
Event data is a powerful data format that allows us to track and analyze things that happen around us. Here’s a handy table comparing entity & event data.
Ready to try using event data to analyze what’s happening? Request a Demo of Keen or schedule a data chat with one of our expert data scientists!



