The other day, Cory (one of our platform infrastructure engineers) sent out a company-wide email about how Keen’s Platform and Middleware Teams were trying to make on-call more manageable. It was a really interesting glimpse into the challenges of ensuring round-the-clock reliability, while also maintaining healthy personal relationships and some degree of sanity.
I thought this might be helpful to other people working on-call and asked Cory if he’d be okay with sharing his original email on the blog. Always eager to help, he said yes, so here it is! –Kevin
Hello party people!
Recently I was chatting with some folks and realized we’ve not talked much outside of the on-call group as to what’s been going on with on-call. I wanted to take some time to conduct some information out as to what we’ve been doing!
Recap
As many of you know things were pretty rough in February and part of March. A lot of long nights got pulled and we had to resort to swapping people out of on-call a few times to rest folks. We learned a lot. Primarily we learned how to band together to fix problems and help each other out. It was a time of sacrifice that many of us (and our families) are still recovering from.
While we’re here, we want to thank everyone for being so understanding and willing to help. We know many of you wanted to do anything you could to help. You didn’t have knowledge needed (yet!) to sit at a keyboard and fix a busted thing, but you all contributed in your own way and we appreciate it!
First, Current State
We have made huge strides in the last few weeks to improve the on-call situation. The most important metric is people’s attitudes and our rested state. This is hard to measure. From my seat the team is in a much happier place. Many of us have taken small vacations to help shore up our moods and repair some of our relationships.
What is measurable is the number of pages:
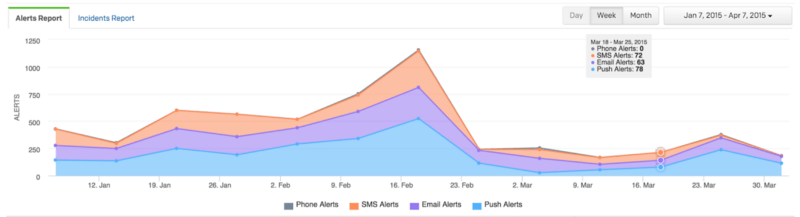
The spikes represents The Troubles™ and we’ve made a huge improvement. The recent uptick is not representative of problems. It’s representative of improvements we’ve made that took some tuning and got sorta noise for a week or so.
I can relay that Jay, who just came off primary on-call last week, called it one of the “lightest” on-call weeks in recent memory. Yay! Congrats to everyone spending so much time on these improvements.
Second, Mechanics
We’ve been meeting regularly to review how on-call works so we can optimize things for everyone. The first thing we decided was that adding new people to the rotation would not immediately help. In fact, as Brooke’s Law describes, it would’ve hurt us as we raced to recover from our problems. We made this clear to some of the new team members. This is not a permanent thing, just a short-term plan to mitigate the blast radius.
Breadth Is Hard
It’s tough to know your way around Keen’s entire stack. Our desire to be polyglot and leverage OSS tools means that we have a lot of stuff for people to learn. So much so that no single person knows how everything works. To that end we’ve begun to specialize our on-call rotation into three categories:
- Stormshield: Cassandra, Storm, some Kafka bits
- Middleware: Pine, Myrrh, Service, LBs, some Kafka bits
- Triage: General overview of everything, meant to help mitigate simple failures and escalate harder ones
Thanks to Kevin, as of last week we officially have two on-call rotations and our alerts are divvied up between 3 escalations. We’re beginning to leverage both on-calls depending on the nature of the failure. This has some great side effects:
- You have a domain expert on hand to help deal with a problem
- You aren’t alone
We’re not done with these mechanical improvements. We’re still meeting every two weeks to iterate toward an on-call that is more approachable. We’re now discussing how to integrate new people and bring down the OMG ON-CALL IS HARD AND LONELY problem. Luckily we have a lot of on-call experience, smarts and compassion.
Third, Infrastructure Improvements
There has been a ton of work in the area of maintenance, bugfixes, upgrades and other contributions from nearly everyone in PLAT and MID. Here are some of the big items:
- Complete overhaul of Zookeeper machines, which coordinate both our Storm and Kafka machines. (Thanks to Brad for keeping this going, which was really scary!)
- Ongoing repair and improvements to our Cassandra data. (Shout out to Brad for stewarding all of the repairs and to Manu and Kevin for working with our Cassandra consultants!)
- Revamp of our fleet of Storm machines to have gobs of memory and not run supervisor instances on our nimbus nodes. (Thanks for Shu for provisioning, overseeing upgrades and making all the changes for this.)
- Overhaul of our “chat ops” deployment system to homogenize the deploy commands for all our stuff. Every Keen-created service is now consistently deployable from @robot! (Thanks to Alan for the revamp and to Shu for continued care and feeding of the bot!)
- Continued improvement of a “query tracing” feature for diagnosing where slowdowns occur and where we can optimize execution of queries. (Thanks to Kevin for introducing this feature and to Manu for his amazing efforts at producing measurable analysis of query execution so that we can compare efforts going forward.)
- Improvements in the efficiency of the compaction path, causing fewer pages and operation issues around compaction, as well as reducing overall load on Cassandra (Amazing effort by Kevin!)
- Pine has evolved and developed a considerable number of protections to keep the service healthy. Some have been bumpy but overall we both stay out of trouble more often, and recover from trouble much faster under it’s supervision of query scheduling.
- Keen-Service has seen dozens of bug fixes and improvements to logging, query tracking, error handling and general maintenance over the last few months. The most recent improvement fixed an oversight where a large number of queries were not being load balanced! (Shout out to Jay and Stephanie for their continued diligence and ingenuity in improving Keen-Service!)
- Our observability and monitoring has been repeatedly improved and rethought across every service within Keen. We have considerably more fine-grained visibility in to how things are behaving from per-queue query durations to visibility in to specific wait times in storm bolts. (Amazing work by Stephanie in testing metrics in Service, Manu in creating Turmeric and every person who handles on call for continually improving our monitoring.)
I’m probably leaving out contributions by a bunch of people. Sorry, I did this from memory and tried to iterate through every major component I could think of.
The Future
Note that we’re not just focused on short term fixes. PLAT is actively working on query performance improvements, data storage/compaction improvements and a bunch of other stuff. MID is working on caching and continued improvements to Keen-Service and it’s future incarnations. There are also 3 new folks that have joined (or will be joining soon) to contribute their considerable experience to the mix. Yay!
Thanks!
On-call shouldn’t dominate our lives. It’s also a necessary and important part of how we maintain the trust our customers place in us every day. We’re lucky enough to work in a company where the power to control this major part of our job is in our hands. To that end we’re working weekly to make on-call an experience that as many people as possible can contribute to. It’s worth nothing that this point in Keen’s history is hard. We’re just big enough to need to specialize, just small enough to not have all the people (yet) that we need to specialize, and all present in a period of growth wherein this transition is hard and messy. Thanks to everyone for working every day to make this a supportive experience.
Henceforth we’ll try and collect information about this every month or so to conduct things out to everyone at Keen. If you’ve got any questions, let me know!


