-
 Streams
Streams
-
Compute
- Overview
- Saved Queries
- Data Explorer Guide
- Group By Ranges & Buckets
- Video Completion Funnel
- Compute Pricing Guide
- Custom Ad Performance
- Session Timing Metrics
- Cohort Analysis
- Retention Analysis
- Funnel Analysis
- Creating a Funnel with an OR Condition
- Stripe Revenue Queries
- Create a Email Nightly Report
- Query Tuning
- Cached Queries
- Cached Datasets
- Paid Session Metrics
- User Engagement
-
Visualize
Cached Datasets
This guide describes how to use Cached Datasets to build a quick, responsive experience for your customer-facing dashboards.
Cached Datasets are a way to pre-compute data for hundreds or thousands of entities at once. They are a great way to improve your query efficiency as well as minimize your compute costs. If you’re looking to cache a single query, check out our separate guide for Cached Queries.
Note: Cached Datasets are currently in Early Release. If you have any questions, or run into any issues while using this feature, please drop us a line.
This guide covers:
- What is a Cached Dataset?
- Sample Use Case
- How to Create a Cached Dataset
- Multi-Analysis with Cached Datasets
- Implementation Tips
- Limits
- Next Steps: Cached Dataset API Reference
What is a Cached Dataset?
Essentially, Cached Datasets are a way to pre-compute data for hundreds or thousands of entities at once. Once setup, you can retrieve results for any one of those entities instantly.
That’s great, but can you give me an example?
Let’s say you are tracking e-book downloads for lots of different authors in a storefront like Amazon. You want to create a report for each author showing how many people are viewing their books, like this:
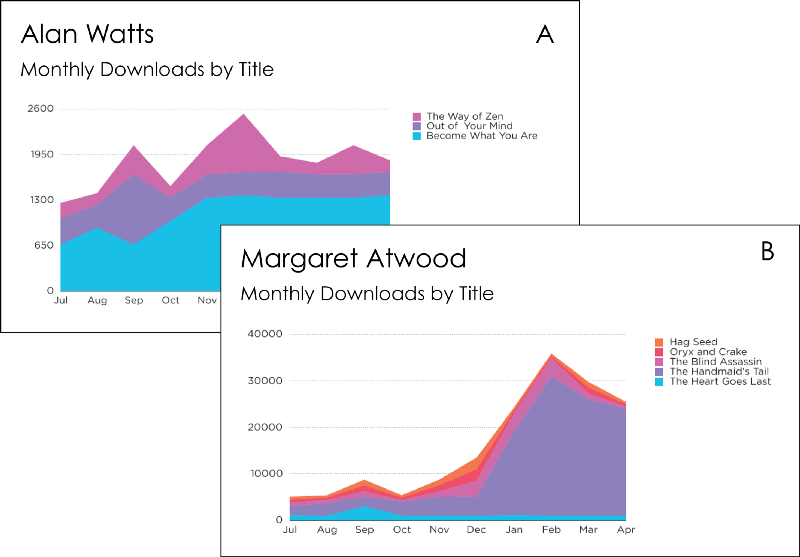
To create this, you would first need to track events each time someone viewed a book like this:
book_download = {
title: "On the Pulse of Morning",
author: "Maya Angelou",
timestamp: "2017-05-18T21:23:49:000Z"
}
Now, we could create a query for each author, where each one would have a filter for that specific author’s name. Here’s one that would retrieve data for Margaret Atwood’s dashboard.
$ curl https://api.keen.io/3.0/projects/PROJECT_ID/queries/count \
-H "Authorization: READ_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"event_collection\": \"download_book\",
\"timeframe\": \"this_10_months\",
\"filters\": [
{
\"property_name\" : \"author\",
\"operator\" : \"eq\",
\"property_value\" : \"Margaret Atwood\"
}
],
\"interval\": \"monthly\",,
\"group_by\": \"title\",
}"
But that would require a lot of overhead. For one, you would have to get the results fresh each time an author requested their dashboard, causing them to have to wait for the dashboard to load. Lastly, the administrative cost is high, because you’d have to create a new query anytime you needed a dashboard for a new author.
Enter Cached Datasets! With Cached Datasets, we can show every author a dashboard that lets them see how each of their books are performing over time, all with a single Keen data structure. It will also just stay up to date behind the scenes, including when new authors are added, and scaling to thousands of authors.
How do I set one up?
Step 1: First, define the query. The basics of the query would be simply counting these book_download events. You will also need to provide an index_by, timeframe, and interval.
-
index_by: In our example, the index would be author, since that’s the property we want to use to separate the results. -
timeframe: This is going to bound the results you can retrieve from the dataset. It should be as broad as you expect ever needing. (Anything outside this timeframe will never be retrievable out of this dataset). In our example, we’re going to go back 24 months. -
interval: This defines how you want your data to be bucketed over time (ex: minutely, hourly, daily, monthly, yearly). In our example, we’re going to do monthly.
index_by properties. All you need to do is specify an array of values for the index_by. Here’s an example of what the syntax would look like:
"index_by": ["prop1", "prop2", "prop3"]
To perform a lookup against such a Dataset you will need to specify values for all of the index_by properties. An example would look like this:
&index_by={"property1":"string_value","property2":5.0,"property3":true}
Note: The above URL parameter should be URL-encoded.
Step 2: Make an API request to kick off that query. Once you do that, Keen will run the query and update it every hour.
Here’s an example request that would create a dataset based on those book_download events. The group_by is what allows us to separate out the views by book title. The PROJECT_ID and all keys will be provided when you create a Keen account.
# PUT
$ curl https://api.keen.io/3.0/projects/PROJECT_ID/datasets/book-downloads-by-author \
-H "Authorization: MASTER_KEY" \
-H 'Content-Type: application/json' \
-X PUT \
-d '{
"display_name": "Book downloads for each author",
"query": {
"analysis_type": "count",
"event_collection" : "book_download",
"group_by" : "title",
"timeframe": "this_24_months",
"interval": "monthly"
},
"index_by": ["author"]
}'
Step 3: Get lightning fast results. Now you can instantly get results for any author. For example, here’s the query you would use to retrieve results for Maya Angelou’s dashboard, showing the last 3 months of downloads:
# GET
$ curl https://api.keen.io/3.0/projects/PROJECT_ID/datasets/book-downloads-by-author/results?api_key=READ_KEY&index_by="Maya Angelou"&timeframe=this_2_months
The results you’d get would look like this (This query was run on April 19th, so the most recent “month” is only 19 days long)
{
"result": [
{
"timeframe": {
"start": "2017-03-01T00:00:00.000Z",
"end": "2017-04-01T00:00:00.000Z"
},
"value": [
{
"title": "I Know Why the Caged Bird Sings",
"result":10564
},
{
"title": "And I Still Rise",
"result":1823
},
{
"title": "The Heart of a Woman",
"result":5329
},
{
"title": "On the Pulse of Morning",
"result":9234
}
]
},
{
"timeframe": {
"start":"2017-04-01T00:00:00.000Z",
"end":"2017-04-19T00:00:00.000Z"
},
"value": [
{
"title": "I Know Why the Caged Bird Sings",
"result":9184
},
{
"title": "And I Still Rise",
"result":7395
},
{
"title": "The Heart of a Woman",
"result":4637
},
{
"title": "On the Pulse of Morning",
"result":8571
}
]
}
]
}
And that’s it! This query, with a timeframe of this_10_months (and different authors) is exactly what was used (along with keen-dataviz.js) to create those awesome dashboards. Here they are again, in case you forgot:
Check out our API Reference to see more of the code samples used to create this dataset.
Multi-Analysis with Cached Datasets
Cached Datasets can also support Multi-Analysis which lets you run multiple types of analyses over the same data. For instance, you could count the number of all the books you’ve downloaded in the previous 2 years, as well as figure out all the unique book titles that are in your book collection, all in one API call!
# PUT
$ curl https://api.keen.io/3.0/projects/PROJECT_ID/datasets/multi-analysis-of-book-downloads \
-H "Authorization: MASTER_KEY" \
-H 'Content-Type: application/json' \
-X PUT \
-d '{
"display_name": "Multi-analysis of book downloads",
"index_by": [
"author"
],
"query": {
"analysis_type": "multi_analysis",
"analyses": {
"total count": {
"analysis_type": "count"
},
"unique titles": {
"analysis_type": "select_unique",
"target_property": "title"
}
},
"timeframe": "previous_24_months",
"timezone": "UTC",
"interval": "monthly",
"event_collection": "book_download"
}
}'
Here are some implementation details:
Tips:
- The
index_byproperty can contain values of any supported type; while strings are the most common (and have a slightly simpler syntax), values that are booleans, numbers, or lists can also be indexed and retrieved. - The interval is unchangeable. If you need results in a different interval, you will need another dataset.
- Datasets run hourly and rerun the last 48 hours. If you are loading historical data, it will not show up in the dataset because data older than 48 hours is not rerun. In order to have the historical data included, you will need to recreate the dataset to capture the older results.
- A dataset with a large timeframe (monthly or longer) that includes the current time (aka timeframes that start with
this) is going to be less efficient from a compute standpoint. This is because as the month (or year) progresses, there is more and more data that has to be recalculated. Potential solutions include changing the relative timeframe fromthis_x_monthstoprevious_x_months(that way it won’t include the current month/year), or changing to a daily interval. - The
timeframeandintervalmust use the same units.
Limits:
- The queries run in the background to fill your dataset with results are run against the Keen platform on behalf of your account. That means they have to abide by all the same rules and rate limiting as your ad-hoc queries (and it’s possible for those queries to force the others to wait, if you’re running a lot of them). This also means that the compute costs incurred by those queries will be added to your bill. In most cases, this is still going to be a lot less than if you would retrieve those results using ad-hoc queries. Cached Datasets are a cost-saving addition.
- A Dataset can have at most 2000 sub-timeframes. If you need to buy yourself some room, you can use a custom interval (something like
every_6_hoursinstead ofhourlywould cut your cardinality down by a factor of 6). - Datasets are restricted by Amazon DynamoDB’s item size limit of 400KB. If a certain dataset result size is over that limit, it will fail to store. To test this, you could run the underlying query of your dataset against the ad-hoc API. Use a filter to replicate a single index value, and timeframe that represents your interval (1-day for daily, 1-hour for hourly, etc.). Just be sure to choose an index value and timeframe that you think represent the largest possible result size. Then zip the payload and check the size of it. If it is over 400KB (or even approaching it), you may have to rethink your model. Some features can greatly explode the size of the results. Mostly, these fall into two categories:
-
group_by’s on a property (or set of properties) that has many distinct values - queries using the
select_uniqueanalysis type that have a high cardinalitytarget_property
-
- Currently, Cached Datasets are not supported via the Keen Explorer.
We’re still building out monitoring for this Early Release feature. If you have any questions, or run into any issues while using this feature, please drop us a line.
